[논문리뷰] GPT-3 : Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
GPT-3 [Paper]
Alec Radford, OpenAI
Preprint, 2020
Contents
LLM/LMM Study Project는 다음 순서로 진행될 예정입니다.
1. ChatGPT
1-1. GPT-1 (https://aipaper-review.tistory.com/1)
1-2. GPT-2 (https://aipaper-review.tistory.com/3)
1-3. GPT-3 (이번 포스팅)
1-4. GPT-4 (https://aipaper-review.tistory.com/5)
2. LLaMA
3. LLaVA
4. DeepSeek
📌 GPT-2 포스트 읽고 오기
2025.02.04 - [LLM] - [논문리뷰] GPT-2 : Language Models are Unsupervised Multitask Learners 논문 리뷰 요약
[논문리뷰] GPT-2 : Language Models are Unsupervised Multitask Learners 논문 리뷰 요약
Language Models are Unsupervised Multitask LearnersGPT-2 [Paper][Code]Alec Radford, OpenAIPreprint, 2019 ContentsLLM Study Project는 다음 순서로 진행될 예정입니다.1. ChatGPT 1-1. GPT-1 (https://aipaper-review.tistory.com/1) 1-2. G
aipaper-review.tistory.com
📌 LLM 연대기 한눈에 보기
| 파라미터수 | Keyword | 효과 | |
| GPT-1 (2018) | 117M | ○ Unsupervised pre-training + Supervised fine-tuning ○ Multi-task 을 위한 Input 변형 ○ Transformer 구조 활용 |
RNN, LSTM 기반 모델보다 훨씬 나은 성능 |
| GPT-2 (2019) | 2B | ○ 웹 크롤링 dataset ○ byte 레벨의 BPE |
인간과 유사한 수준의 텍스트 생성 |
| GPT-3 (2020) | 175B | ○ 더 더 Large dataset ○ 더 더 Large model ○ Few-shot learning |
그 당시의 아무리 모델이 커도 성능 한계가 있다는 여론 => 응~ 아냐~ 모델 데이터 다 때려박으면 성능 올라감~ 인간보다 뛰어난 성능 |
| GPT-4 (2023) | unknown | ○ Multi-modal ○ 강화학습 기반 fine-tuning |
이미지-텍스트 인풋 -> 텍스트 생성 |
Summary

- 175B 파라미터의 거대 모델 Language Model로 scale-up 하여 task-agnostic, few-shot 성능을 향상시켰다
- GPT-3 모델은 어떠한 쿼리들로부터 gradient를 업데이트하지 않음
- 1) few-shot learning, 2) one-shot learning, 3) zero-shot learning 상황에서 다양한 실험 진행
Motivation
- 현 딥러닝 학습 패러다임은 task-agnostic한 구조(ex, Transformer) 을 활용하지만, 여전히 task-specific task에서의 성능을 위해선 task-specific 데이터셋과 fine-tuning 이 필요하다. 이는 다음과 같은 이유로 개선되어야 함.
- 현실적인 측면에서 언어모델의 aplicability 을 위해 모든 task마다 거대 labeled 데이터셋을 만들 수 없음
- pre-training 단계에서 굉장히 많은 정보를 획득하기로 설계된 거대 모델이 fine-tuning 단계에서 굉장히 작은 데이터로 튜닝되는 패러다임 형식은 오히려 out-of-distribution (OOD) 정보에 취약함 -> train 데이터 분포에 매우 overfit 되기 때문
- 딥러닝 모델과 달리, 사람은 새로운 task에 적응하기에 large dataset을 요구하지 않음! 몇 가지 예시만 들어주면 (few-shot learning), 사람은 잘 하는데 모델도 할 수 있지 않을까?
Method

논문 핵심 : 더 큰 모델, 더 큰 데이터셋, 더 길게 학습 !

논문에서는 Few-shot learning에 대해서 굉장히 많은 부분 설명함.
(Zero-shot, One-shot, Few-shot 에 대한 설명은 위의 그림으로 대체함)
이때, In-Context Learning 시 어떠한 gradient update도 하지 않음!
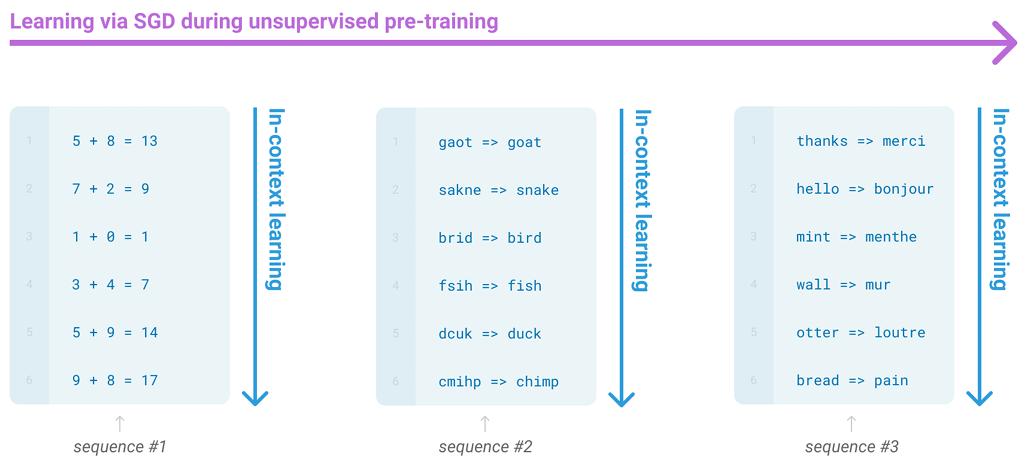
* In-Context Learning 이란...
모델이 몇 가지 예시를 보고 패턴을 이해하고 답을 생성하는 능력을 뜻함
사람이 new task를 위해 new 데이터셋을 학습하지 않는 것처럼, 몇 가지 예시만을 보고 패턴을 유추하는 능력
- 어떠한 파라미터 업데이트는 하지 않음!
- 프롬프트 (shot) 이 많아질수록 능력 향상

1. Natural Language Prompt > No prompt
- 자연어 설명은 모델 성능에 도움을 준다
2. 프롬프트 갯수(K) 에 비례하여 성능 증가
- 예제가 많을 수록 도움을 준다
3. 모델이 클수록(175B) in-context 정보를 더 잘 활용
Model and Architectures

모델구조는 GPT-2 와 동일함
- 레이어 초기화 : 1/√N (N: 레이어 갯수) scaling
- pre-normalization
- reverisble tokenization (maybe BPE를 말하는 듯?)
- dense - sparse attention 을 번갈아 사용 (like Sparse Transforemr)

엄청 큰 모델을 길게 학습시키는 것이 성능이 최고더라~
Experiment
- LAMABADA : 문맥을 읽고 마지막 단어 완성하기 -> 긴 문맥을 이해할 수 있는 능력 (word of long dependency)
=> SOTA 보다 높음- 예시 : He locked the door and hid the treasure under the ____ -> bed

- HellaSwag : 상식과 논리를 바탕으로 문장의 자연스러운 흐름을 예측 => SOTA 보다는 낮음
- 예시 : A person is assembling a piece of furniture. They insert the first screw and then...
(A) start eating a sandwich. ❌
(B) tighten it with a screwdriver. ✅
(C) run outside to play basketball. ❌
(D) begin singing a song. ❌
- 예시 : A person is assembling a piece of furniture. They insert the first screw and then...
- StoryCloze : 짧은 이야기(4~5문장)에서 마지막 문장을 예측 => 기존의 zero-shot 성능보다 10% 증가 but BERT 기반 모델보다는 4% 낮음
- 예시 : John woke up early in the morning. He packed his bag and left for the airport. He checked in and waited for his flight. When he finally boarded the plane, he...
(A) fastened his seatbelt and prepared for takeoff. ✅
(B) jumped out of the window and ran away. ❌
- 예시 : John woke up early in the morning. He packed his bag and left for the airport. He checked in and waited for his flight. When he finally boarded the plane, he...
- Open-Domain QA :

... 굉장히 많은 실험은 논문을 참고하세요
Ablation Study
Measuring and Preventing Memorization Of Benchmarks

대용량의 웹 데이터셋이면, 이미 test 셋이 학습 때 중복되어 cheat 아닌가 에 대한 분석 -> GPT-2 에서 이미 분석한 내용이지만, GPT-3에서는 데이터와 모델 크기가 너무 커져서 데이터 중복과 데이터 암기에 대한 분석이 더 필요함
그러나 결론은 1) train/eval 데이터셋 간의 데이터 중복은 굉장히 적어서 그 영향이 굉장히 미미하고, 2) 모델이 여전히 underfitting 한 상태인 것으로 보임 -> 문제없다!