Improving Language Understanding by Generative Pre-Training
GPT-1 [Paper]
Alec Radford, OpenAI
Preprint, 2018
Contents
LLM/LMM Study Project는 다음 순서로 진행될 예정입니다.
1. ChatGPT
1-1. GPT-1 (이번 포스팅)
1-2. GPT-2 (https://aipaper-review.tistory.com/3)
1-3. GPT-3 (https://aipaper-review.tistory.com/4)
1-4. GPT-4 (https://aipaper-review.tistory.com/5)
2. LLaMA
3. LLaVA
4. DeepSeek
📌 LLM 연대기 한눈에 보기
| 파라미터수 | Keyword | 효과 | |
| GPT-1 (2018) | 117M | ○ Unsupervised pre-training + Supervised fine-tuning ○ Multi-task 을 위한 Input 변형 ○ Transformer 구조 활용 |
RNN, LSTM 기반 모델보다 훨씬 나은 성능 |
| GPT-2 (2019) | 2B | ○ 웹 크롤링 dataset ○ byte 레벨의 BPE |
인간과 유사한 수준의 텍스트 생성 |
| GPT-3 (2020) | 175B | ○ 더 더 Large dataset ○ 더 더 Large model ○ Few-shot learning |
그 당시의 아무리 모델이 커도 성능 한계가 있다는 여론 => 응~ 아냐~ 모델 데이터 다 때려박으면 성능 올라감~ 인간보다 뛰어난 성능 |
| GPT-4 (2023) | unknown | ○ Multi-modal ○ 강화학습 기반 fine-tuning |
이미지-텍스트 인풋 -> 텍스트 생성 |
Summary

- 2-stage로 이루어진 semi-supervised 학습 방식
- 방대한 unlabeled dataset을 활용한 unsupervised pretraining
- input-transformations을 활용한 세부 task에 특화된 supervised fine-tuning
- 텍스트의 long-term dependency에 강인한 transformer decoder 구조 채택
- QA, semantic similairty, entailment determination, text classification 등 다양한 NLP task에서 우수한 성능 달성
Motivation
1) 방대한 양의 unlabeled data를 활용하여 general한 언어 능력을 키우고, 2) task에 맞는 input을 변형하여 추가적인 모델 구조 변형 없이 최소한의 비용으로 specific 한 task를 수행하도록 한다.
Method
1. Unsupervised pre-training
Multi-layer Transformer Decoder 구조를 언어 모델로 활용한다.
Language Modeling Objective :

- 이전 token U(uk, uk+1, ..., ui-1)들이 주어져있을 때 다음 token (ui) 을 예측하는 모델

- context vector (U) 와 embedding matrix (We)를 곱하고 position embedding (Wp)를 더한 후 n 개의 transformebr block을 거친 후 taret token (P) 를 생성함.
- SGD 기법을 활용하영 backpropagation을 함.
2. Supervised fine-tuning
마지막 transformer block 이후 추가적인 linear output layer을 거친 후 최종 아웃풋을 생성한다.
이 단계에서 추가되는 parameter은 lineay output layer와 delimitier token 뿐이다.
Unsupervised pre-training 단계의 language model objective 은 1) supervised model의 generalization 향상, 2) 빠른 convergence에 도움을 준다.
3. Task-specific input transformations

각 task마다 전체적인 transformer 구조나 training objective는 동일하지만, 세부 task를 위해서 input을 변형하여 사용한다. (최소한의 추가 비용을 위하여)
- Classficiation :
- 주어진 카테고리, 감정, 스팸 탐지 등을 분류하는 task
- linear [ trans [ <start> text <extract> ] ] (그대로 변형 없이 사용)
- Textual entailment :
- 전제 p 가 참일 때, 주어진 가설 h 사이의 관계를 설명하는 task
- Entailment (함의): 전제가 참이면 가설도 반드시 참이어야 함.
- Contradiction (모순): 전제가 참이면 가설이 거짓이어야 함.
- Neutral (중립): 전제가 참이어도 가설이 참인지 거짓인지 알 수 없음.
- 예시
- 전제: "A man is playing the guitar." vs 가설: "A person is playing a musical instrument." -> Entailment
- 전제: "A man is playing the guitar." vs 가설: "A man is performing on stage." -> Netural
- linear [ transf [ <start> 전제 p <delim> 가설 h <extract> ] ]
- 전제 p 가 참일 때, 주어진 가설 h 사이의 관계를 설명하는 task
- Similarity
- 두 문장 p1, p2 가 주어져 있을 때 얼마나 의미론적으로 유사한지 추정하는 task
- 예시
- 1. 높은 유사도 (High Similarity)
- p1 : "나는 오늘 아침에 커피를 마셨다." vs p2 : "오늘 아침에 나는 커피를 마셨다."
- → 단어 순서만 다르고 의미는 동일 → 유사도 높음
- p1 : "나는 커피를 좋아한다." vs p2 : "아침마다 커피를 마신다."
- → 두 문장이 커피와 관련 있지만 같은 의미는 아님 → 중간 정도의 유사도
- p1 : "나는 커피를 마셨다." vs p2 : "오늘 날씨가 정말 좋다."
- → 의미적으로 거의 관련 없음 → 유사도 낮음
- 두 문장의 순서는 의미 없으므로, 독립적으로 2가지 케이스를 모두 고려
- linear [ [ transf [ <start> p1 <delim> p2 <extract> ] + transf [ <start> p2 <delim> p1 <extract>] ] ]
- Multiple Choice
- 질문에 해당하는 정답을 고르는 task (단일, 다중정답)
- 예시
- 다음 중 포유류에 해당하는 동물을 모두 고르시오.
(A) 개 ✅
(B) 독수리
(C) 돌고래 ✅
(D) 뱀
- 다음 중 포유류에 해당하는 동물을 모두 고르시오.
- softmax ( linear [ [ transf [ <start> p1 <delim> p2 <extract> ] ], linear [ [ transf [ <start> p1 <delim> p2 <extract> ] ] , ... )
Experiment
다양한 NLP 분야에서 SOTA 성능을 달성했다고 한다.

Ablation Study

Left) pretrained LM -> target task로 transfer하는 layer을 증가할 수록 성능이 좋아짐 -> pretrained LM의 각 layer가 target task에 적합한 기능을 수행하였다는 뜻.
Right) 다양한 task에서 LSTM보다 Transformer 구조가 성능이 더 좋다는 것을 알려준다.
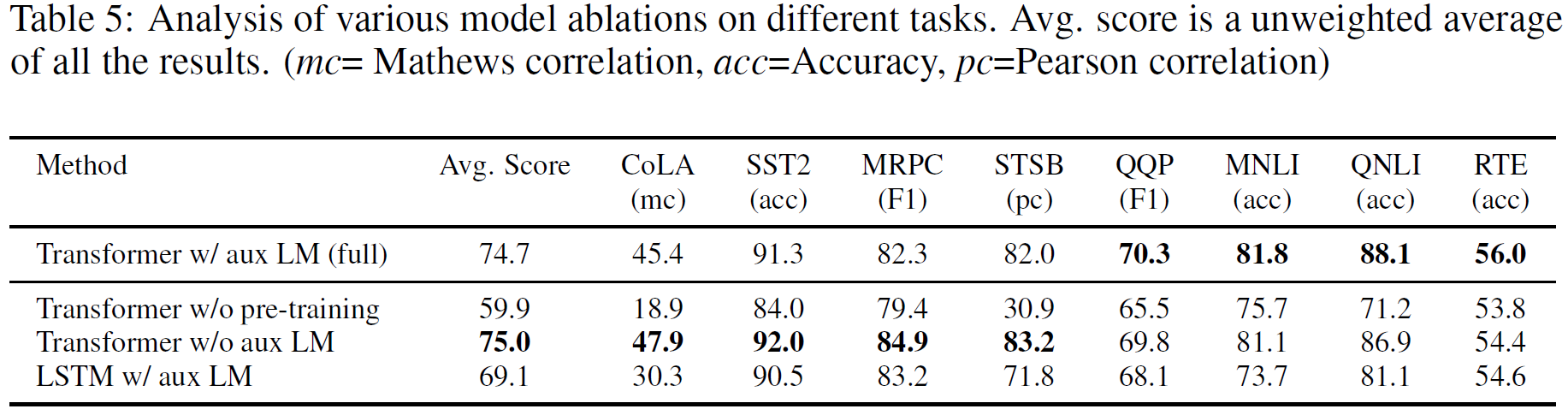
1. aux LM (=unsupervised language model objective) 의 효과성
2. Transformer vs LSTM 의 효과성
My Opinion
- GPT-1 은 NLP 분야에서의 pre-training 을 대중화시킨 첫 번째 논문이다. (지금은 별 거 아니지만, 그때 당시에는 획기적인 논문이였음.)
- GPT-2 드루와... 가보자고~
'LLM' 카테고리의 다른 글
| [논문리뷰] LoRA : Low-Rank Adaptation of Large Language Models (0) | 2025.02.25 |
|---|---|
| [논문리뷰] GPT-4 Technical Report (0) | 2025.02.06 |
| [논문리뷰] GPT-3 : Language Models are Few-Shot Learners (0) | 2025.02.06 |
| [논문리뷰] GPT-2 : Language Models are Unsupervised Multitask Learners 논문 리뷰 요약 (0) | 2025.02.04 |