LoRA : Low-Rank Adaptation of Large Language Models
LoRA [Paper][Code]
Edward Hu, Microsoft
ICLR, 2022
Contents
LLM/LMM Study Project는 다음 순서로 진행될 예정입니다.
1. ChatGPT (https://aipaper-review.tistory.com/1)
2. LLaMA
3. LLaVA
4. DeepSeek
📌 LLaVA-NeXT-Interleave 포스트 읽고 오기
[논문리뷰] LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal ModelsLLaVA-NeXT-Interleave [Paper][Code]Feng LiPreprint, 2024 ContentsLLM/LMM Study Project는 다음 순서로 진행될 예정입니다.1. ChatGPT (https://aipaper
aipaper-review.tistory.com
Summary

- pre-trained weight는 freeze 한 채로, 트랜스포머 layer 마다 학습 파라미터 rank decomposition matric W 만을 학습하여 pre-trained weight + W 연산으로 inference -> 추가적인 layer, depth 필요 X = inference latency X
- fine-tuning 때 학습 파라미터의 갯수를 10,000배까지 줄이면서 downstream task에 잘 적용할 수 있는 LoRA 기법 제안
Motivation
- fine-tuning을 위해서 기존 연구들은 pre-trained 모델의 모든 파라미터를 전체 다 학습시키는 방식으로 진행
-> 그러나, LLM 같이 굉장히 큰 모델을 전체 학습시키는 것은 굉장히 피로함 - 다양한 기법들이 연구되었지만 model depth를 키우던가 or input token 앞에 learnable token을 추가하는 방식
-> 이는 inference latency를 요구하고, 넣을 수 있는 문장의 길이를 짧게 만드는 한계가 있음. - 우리는 inference latency 없이 전체 pre-trained weight를 다시 학습시키는 과정이 필요가 없는, 학습시켜야하는 파라미터 수가 굉장히 적은 LoRA을 제안함
- over-parametrized models in fact reside on a low intrinsic dimension (rank)
- pre-trained weight를 고정하면서, dense layer의 업데이트를 rank decomposition (행렬 분해) 하여 간접적으로 모델을 학습시키는 방식 채택
Method
Background
Rank 개념 :
- (in 행렬) 서로 선형 독립인 벡터의 갯수를 뜻함
- 예시

- 위 행렬의 rank 는 2임.
- 두 번째 행 (3,6)은 첫 번째 행 (1,2)의 3배이므로, 선형 독립이 아님 -> rank = 2
- 여기서 (3, 6) 벡터는 크게 유의미한 정보가 아닐 수 있음 !
- 예시
- (in 딥러닝) like 유의미한 정보를 담고 있는 차원 (embedding space) 이라고 이해할 수 있음
고차원에서 모든 차원이 유의미한 정보를 담고 있지 않음 -> 특정 차원에서 유독 더 중요한 정보를 담고 있음.
=> 딥러닝 모델도 마찬가지임.
=> 우리는 특히 더 중요한 정보만을 압축 (~= low intrinsic rank) 해서 추출할 수 있다면, 고차원의 파라미터/메모리를 쓰지 않고도 비슷한 성능을 낼 수 있을 것.
특정 레이어, 채널, 차원 등에서 유의미한 정보만 쏙쏙 골라서 경량화/좋은 성능을 내는 연구는 많이 있었음.
(like 깔때기 원리!! - 알갱이만 쏙쏙 뽑아 액기스만 쓴다)

이런 종류의 유명한 연구들로는 ....
1) 쏙쏙 알맹이를 뽑아 성능을 올리는 기능적인 기법
ex. VAE : 압축한 latent vector을 reconstruct 해서 원본이미지가 잘 복원되면 latent vector가 유의미한 정보를 잘 뽑았구나!

2) 필요한 알맹이를 뽑아 경량화를 하는 기법
ex. Vector Quantization : 비슷한 원리로 최종 audio가 잘 생성되었다면 codebook 의 vector들이 잘 특징을 추출했구나
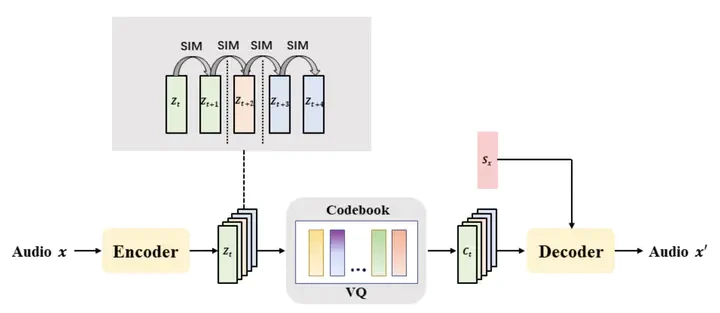
+ 그러나 무조건 줄인다고 해서 좋은 건 아님. 오히려 확장시키는게 좋을 수도 있다.
그 중 제일 유명한 구조는....
대부분이 잘 아는 트랜스포머 Feed-Forward 구조임.
무려 4배로 dimension을 확장시켰다가 다시 줄이는 정반대의 구조를 채택.

+ 어떤 킹왕짱 논문에서는 차원을 확장시키면서도 좋은 알맹이를 뽑을 수 있는 방법을 제시하는데...
.
.
.
그건 바로.... 킹왕짱 본인이 쓴 논문이다. (비밀이다.)
LoRA
Low-Rank-Parametrized Update Matrices
논문은 매우 간단하다.
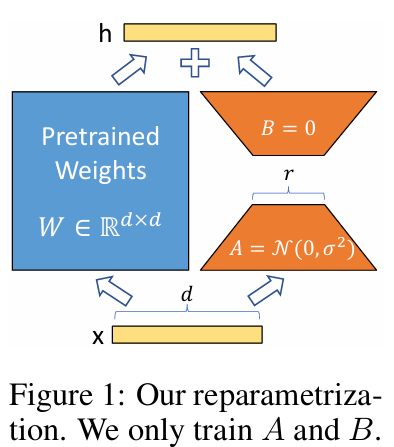

Pre-trained 모델의 weight W는 freeze 하고, 추가한 learnable A 와 B 파라미터만을 fine-tuning 한다.
이후, weighted-sum 형태로 최종 아웃풋을 생성.
+ A는 random gaussian initialization으로 시작하고, B는 0으로 시작하여 BA의 초깃값은 0이다.
이때, △W = BA 형태로, B = (d x r), A = (r x d) 차원으로 이루어져 있음.
여기서 r 은 굉장히 작은 scalar로, 논문에서는 1, 4, 8 수준으로 설정하고 있음.
따라서 학습시켜야할 파라미터수가 굉장히 작고, inference 시에는 단순히 pre-trained weight W 에 BA를 더해주기만 하면 되서 추가의 latency가 필요하지 X.
또한, task가 바뀔 때마다 BA 를 B'A' 로 바꿔주기만 하면 되서 굉장히 심플하게 다양한 task에도 적용가능.
+ 기존 기법에도 바로 적용할 수 있음 (ex. prefix-tuning)
Applying LoRA to Transformer
본 논문에서는 self-attention 모듈의 Key, Query, Value의 attention_weight와 Output의 projection_weight,에 LoRA 모듈을 적용함.
결과적으로 좋은 성능을 보였다고 한다!
Experiments




Ablation Study



'LLM' 카테고리의 다른 글
| [논문리뷰] GPT-4 Technical Report (0) | 2025.02.06 |
|---|---|
| [논문리뷰] GPT-3 : Language Models are Few-Shot Learners (0) | 2025.02.06 |
| [논문리뷰] GPT-2 : Language Models are Unsupervised Multitask Learners 논문 리뷰 요약 (0) | 2025.02.04 |
| [논문리뷰] GPT-1 : Improving Language Understanding by Generative Pre-Training 논문 리뷰 요약 (1) | 2025.02.03 |